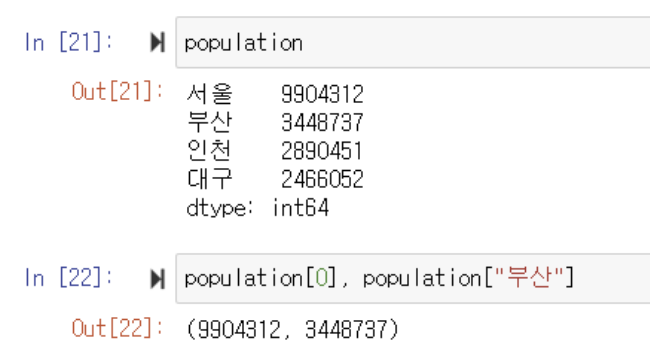
▶️ 위에서 이미 pd.Series값을 변수 population에 저장해두었음
▶️ 변수[index 순서] 혹은 변수['index명']을 입력함으로써 value값을 출력할 수 있음
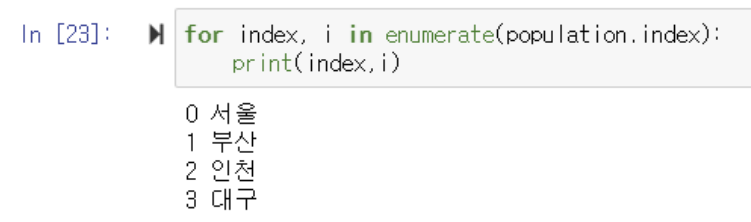
▶️ 지정한 index값이 아닌 0번부터 순서대로 index를 지정할 수 있음

▶️ index 순서를 원하는 순서대로 배열함으로써 데이터를 섞어서 만들 수 있음

▶️ 위와 유사하게 원하는 index값만 배열함으로써 value값을 추출할 수 있음

▶️ 변수<특정값
→ 특정값보다 작은 value값을 가진 index는 True, 그렇지 않은 index는 False값을 출력함
▶️ 변수[변수<특정값]
→ 특정값보다 작은 value값을 가진 index와 value만 출력함

▶️ 200,000보다 크고 5,000,000보다 작은 value값을 가진 index를 출력하고자 할 때 따로 따로 출력해도 되지만 & 연산자를 이용해 동시 출력도 가능함

▶️ 딕셔너리의 인덱스 슬라이싱과 비슷함
→ 1번부터 2번 인덱스 값만 출력함

▶️ index값이 '부산'부터 '대구' 사이에 있는 index와 value값을 출력함
★ index 수치를 슬라이싱할 때와는 다르게 끝 값 -1 적용하지 않음 ★

▶️ 변수.keys()를 통해 index값을 모두 출력할 수 있음

▶️ 특정 index의 value값을 출력하고자 할때는 변수['index명'] 혹은 변수.index명을 활용할 수 있음

▶️ 특정 index값이 변수 내에 존재하는 지 확인하는 방법
→ 존재하면 True, 존재하지 않으면 False값을 출력함

▶️ 딕셔너리와 유사하게 .items를 통해서 key값과 value값을 모두 가져올 수 있음

▶️ 특정 index값을 Null값으로 만들고자 하는 경우 변수['index명'] = None을 활용
⇒ 이후 변수를 출력해보면 특정 index가 None으로 출력됨

▶️ 변수.isnull()을 활용하면 변수 내에 None값을 가진 index만 찾아낼 수 있음
→ None값을 가지고 있으면 True, 그렇지 않으면 False로 출력됨

▶️변수[변수.isnull()]을 활용하면 None값은 가진 index만 출력할 수 있음

▶️df['index명']을 통해 해당 index의 value값을 출력할 수 있음

▶️ indexing이 2번 들어간 모습으로, '지역'의 value값 중에서도 0번 인덱스 값만 출력함

▶️ df['index명']에서 index이름은 리스트 형태로 입력이 가능함

▶️ 딕셔너리에서 했던 슬라이싱과 마찬가지로 [0: ]은 0번부터 끝까지를 의미함 → 행단위로 전체 df을 출력함
'Data Analysis' 카테고리의 다른 글
| MBTI 데이터 분석 프로그램 (0) | 2021.09.02 |
|---|---|
| [ Python ] 데이터 (0) | 2021.09.02 |
| [ Python ] 모듈 (0) | 2021.09.02 |
| [ Python ] 클래스 (0) | 2021.09.02 |
| 유튜브 댓글 크롤링 프로그램 (3) | 2021.09.02 |