Machine Learning
- Deep Learning
→ Machine Learning의 부분집합
→ 최근 여러 분야에서 두각을 나타내고 있어 별도의 학문처럼 인식되어짐

▶ Artificial Intelligence, 인공 지능 : 사고방식이나 학습 등 인간이 가지는 지적 능력을 컴퓨터를 통해 구현하는 기술
▶ Machine Learning, 머신러닝 : 컴퓨터가 스스로 학습하여 인공지능의 성능을 향상시키는 기술 방법
▶ Deep Learning, 딥 러닝 : 인간의 뉴런과 비슷한 인공신경망 방식으로 정보를 처리

지도학습(교사 학습)?

문제와 정답을 모두 알려주고 공부시키는 방법
→ 종속변수 존재, 모델 성능 평가 가능
- Teachable Machine → 'Supervised Learning'
⇒ 누구나 machine learning model을 쉽고 빠르고 간단하게 만들 수 있도록 제작된 웹 기반 도구

▶️ 구글에 teachable machine 입력 후 가장 첫 페이지 클릭
Teachable Machine
Train a computer to recognize your own images, sounds, & poses. A fast, easy way to create machine learning models for your sites, apps, and more – no expertise or coding required.
teachablemachine.withgoogle.com

▶️ 시작하기 클릭

▶️ 여러 프로젝트 중 이미지 프로젝트를 예시로 들어봄

▶️ 표준 이미지 모델 선택

▶️ 웹캠을 켜주고 길게 눌러 녹화하기를 선택하면 연속으로 사진이 촬영됨
▶️ 주먹 / 가위 / 보를 machine learning이 잘 인식하는지 확인하기 위해 클래스를 3가지 형성해 각각의 사진을 촬영함
▶️ 학습하기 버튼 클릭
▶️ 여러 각도에서도 주먹 / 가위 / 보를 잘 파악하는 결과물을 볼 수 있음
비지도학습(비교사학습)?

답을 가르쳐주지 않고 공부시키는 방법
→ 종속변수 부재, 모델 성능 평가가 어려움
강화학습?

보상을 통해 상은 최대화, 벌을 최소화하는 방향으로 행위를 강화하는 학습
→ 어떤 환경 안에서 정의된 에이전트가 보상을 최대로 하는 행동을 선택
⇒ 게임에서 예시로 사용되는 모습

- Feature Engineering
→ feature는 변수

빨간색
과일
둥근 모양
달콤한 맛
⇒ 위 사진이 사과인지 구분하기 위한 변수(특징)이 필요함
▶️ 실제 사례
- K-means Clustering

→ 주어진 데이터를 k개의 군집으로 묶는 알고리즘
→ 최초 k 값 선정이 어려워 계층적 군집분석을 활용하기도 함
→ 평균을 기준으로 계산하기에 이상치에 민감함
★ 이상치에 대응하기 위해 중앙값을 기준으로 사용하는 k-medoid clustering을 사용하기도 함 ★
- Hierarchical Clustering, 계층적 군집

→ 관측치간 거리(유사성)을 측정하여 군집을 만들고 이를 계층화 하는 방법
→ 계층도(dendrogram)을 활용한 데이터 특성 파악 용이(k 개수 선정)
→ 유사도 측정에는 최단 거리, 최장 거리, 평균 거리, WARD 측정 방법이 있음
- Decision Tree, 의사 결정 나무

→ 분류 나무(Classification Tree)는 종속변수가 이산형인 경우(나눌 수 있는 경우) 사용
→ 의사결정규칙(decision rule)을 도표화하여 종속변수를 분류(classification) 하는 방법
→ 속성공간에서 출력 변수가 유사한 데이터끼리 분할하는 지표(동질성)가 필요하며 Entropy, 지니계수의 개념 사용

Entropy ⇒ 불확실성, 판별어려움으로 해석할 수 있음

▶️ Entropy가 커질수록 모델이 빨강과 파랑을 구별하기 어려움
⇒ Example
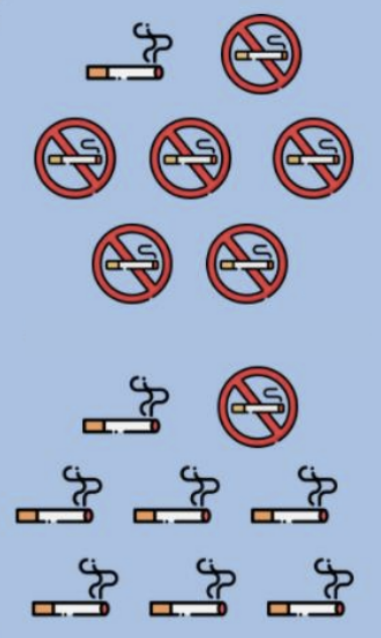
▶️ 흡연자와 비흡연자 전체 15명이 존재함
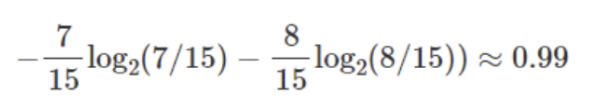
▶️ 15명의 Entropy를 계산하면 위와 같음



▶️ Entropy가 0.99에서 0.57로 줄어들었음
→ Entropy가 낮아졌기(=순수도가 증가) 때문에 분할하는 게 낫다는 결론
'Data Analysis' 카테고리의 다른 글
| [ Python ] 모델 (0) | 2021.09.10 |
|---|---|
| 데이터 추출 연습 (0) | 2021.09.09 |
| [ Python ] 그룹(Groups) (0) | 2021.09.09 |
| [ Python ] 범위 (0) | 2021.09.09 |
| [ Python ] 수량자 (0) | 2021.09.09 |