Model

▶️ 데이터를 load하기 전에 pandas를 먼저 import함

▶️ 이전에 했던 방법과 동일하게 mbti 엑셀 파일을 같은폴더에 저장하고 df에 저장함

▶️ 복습 겸 데이터가 잘 저장 되었는지 확인
- Preprocessing, 정규 표현식

▶️ 정규표현식을 사용하기 위해 re를 import 해줌
▶️ 8674 회원의 comment를 vertical bar( | )를 기준으로 분할하고 0번과 1번 index의 comment를 출력함

▶️ 1번 index의 comment는 MBTI를 분석하는 데 필요없기 때문에 삭제하려고 함
→ needToBeRemoved 변수에 저장

▶️ needToBeRemoved에 저장된 것에서 http 혹은 https로 시작하는 comment를 공백으로 대체함
▶️ string에서는 replace를 사용했지만 re에서는 sub를 사용함
▶️ 공백이 출력된 모습을 보니 잘 제거됨
★ 0번부터 8674번의 회원 comments 전체에서 8674번 회원의 comment 하나를 제거하기는 복잡할 수 있음 ★
⇒ 순서 정하기(한 문장 제거 → 8674번 회원의 전체 comment에서 한 문장 제거 → 0번부터 8674번 전체 회원들의 comments에서 한 문장 제거)
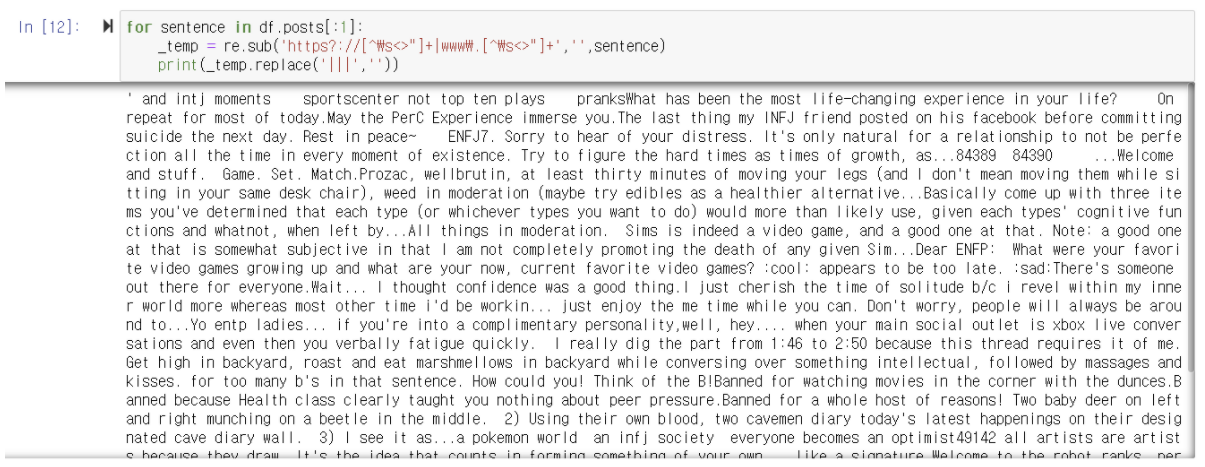
▶️ 이제는 8674번의 comment 전체 내에서 'https?://[^\s<>"]+|www\.[^\s<>"]+'에 해당되는 comment를 공백으로 변환하려고 함
▶️ 두 번째 줄에서는 re.sub를 쓰지만 세 번째 줄에서는 _temp.replace를 쓰는 이유는 세 번째 줄이 string class이기 때문

▶️ remove_sth 사용자 정의 함수를 만들어 http 혹은 https로 시작하는 comment와 |||를 공백으로 바꾸도록 만듦

▶️ 위 셀을 다음과 같이 표현할 수도 있음

▶️ 이번엔 0번부터 8674 회원 전체의 comments에서 remove_sth 사용자 정의 함수가 작동하도록 map 함수를 사용해 post_removed_series 변수에 저장함

▶️ 0번부터 8674 회원 모두의 comments에서 공백으로 잘 변한 모습
- 데이터 형태 맞추기

color에 저장된 text를 변수로 만들어 index에 저장하는 과정
→ text 그대로는 model에 넣을 수 없어 encoding 해줘야함
★ one-hot encoding은 vector라고도 부름 ★
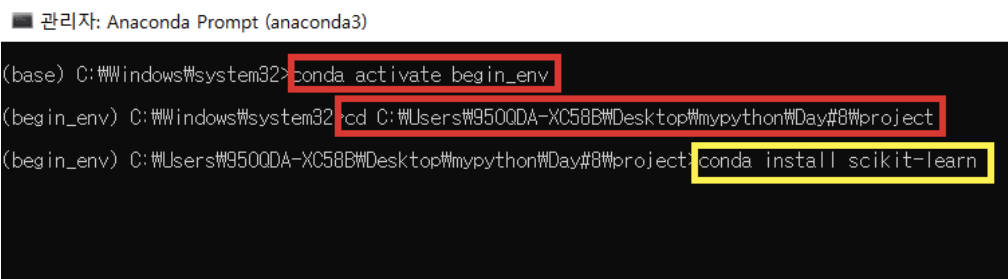
▶️ anaconda prompt를 실행해 아나콘다를 활성화 시킴
▶️ project가 저장된 폴더로 주소 변경
▶️ conda install scikit-learn을 설치
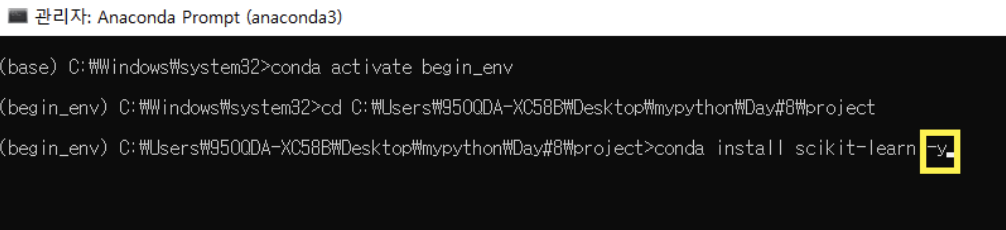
▶️ conda install scikit-learn 뒤에 -y를 추가적으로 작성해주면 중간에 y/n를 물어보는 과정에서 자동으로 y가 선택됨

▶️ done이 뜨면 설치 완료

▶️ scikit-learn은 machine learning 알고리즘을 모아둔 패키지임

▶️0번부터 8674번까지의 회원 comments를 분석하다보면 겹치는 단어들이 많이 생김
→ MBTI를 분석하는 데 필요 없음
▶️ 이런 단어들이 나올 때는 5000개까지만 나오도록 설정하고, stop words는 english로 설정함
NLTK's list of english stopwords
GitHub Gist: instantly share code, notes, and snippets.
gist.github.com

▶️ 이번에는 post_list라는 변수에 빈 리스트를 저장함
▶️ for문이 돌아가면서 post_removed_series에 저장된 값이 하나씩 sentence에 더해짐

▶️ 모두 저장된 후 0번부터 8674번까지의 회원의 post_list의 길이는 8675가 됨

▶️ 모든 회원들의 comment가 리스트에 잘 저장된 모습

▶️ transform은 리스트를 vectorizer로 만들고 배열 형태로 변환시킴(array 형태)
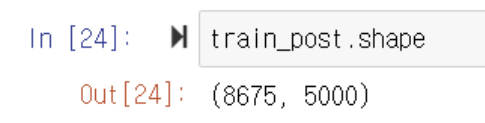
▶️ 위에서 max_features를 5000으로 제한뒀기 때문에 train_post의 shape을 출력해보면 열이 5000으로 제한된 모습을 볼 수 있음
- 레이블 인코딩
→ 문자를 숫자로 바꿔줌

MBTI의 레이블 인코딩은 몇 개 일까?
⇒ 총 16개이므로 0번부터 15번까지 나옴

▶️ 레이블 인코더는 .fit 함수를 사용함
- Model

▶️ 의사결정나무를 import 해줌

▶️ 이 때 max_depth는 entropy 구분을 몇 번 할건지를 의미함
- Train
→ 전처리 하기 전에 train과 test를 나눠야 함
→ train은 모의고사, test는 실전 문제라고 생각하면 편함

▶️ train을 학습시킴
- Prediction

▶️ 특정 데이터(Full Dataset)를 받았을 때, 학습을 하고 예측을 함
→ 이미 풀어본 모의고사를 그대로 받고 다시 풀어보는 행위
▶️ 예측은 한 번도 접해보지 못한 데이터를 가지고 예측해야 좋은 모델을 만들 수 있음

▶️ 이 코드도 마찬가지로 모의고사 문제를 다 풀고 답지를 본 후에 다시 동일한 모의고사를 푸는 행동과 같음
- Evaluation

▶️ 위에서 설치한 sklearn 패키지에서 accuracy_score와 confusion_matrix를 import해줌

▶️ accuracy_score를 통해 target_pred과 train_target의 정확도를 보니 약 80퍼센트 정도의 예측률을 가짐

▶️ 각 유형별 정확도를 확인할 수 있는 Confusion Matrix를 conda prompt에서 설치해줌

▶️ conda install -c conda-forge scikit-plot -y 설치

▶️ 설치 후 위 셀을 import하면 confusion_matrix가 나옴

▶️ target_encoder의 class 값들은 array 형태로 배열됨

▶️ enumerate 함수를 사용하면 각각의 값들을 index와 함께 출력할 수 있음
★ 새로운 데이터로 예측해보자! ★

▶️ 새로운 데이터를 new 변수에 저장함

▶️ new 변수에 저장된 값을 vectorizer로 만들고 array 형태로 배열시킴

▶️ 이 new_train을 예측해보면 array([9]) 값을 출력함

▶️ .inverse_transform([array 값]) : 숫자로 된 레이블 인코딩을 텍스트로 변환시켜줌
⇒ array 9번에 저장된 INFP가 출력됨
'Data Analysis' 카테고리의 다른 글
| 머신러닝(Machine Learning) (0) | 2021.09.09 |
|---|---|
| 데이터 추출 연습 (0) | 2021.09.09 |
| [ Python ] 그룹(Groups) (0) | 2021.09.09 |
| [ Python ] 범위 (0) | 2021.09.09 |
| [ Python ] 수량자 (0) | 2021.09.09 |